1. 论文信息
论文标题:Focal Loss for Dense Object Detection
论文来源:IEEE Transactions on Pattern Analysis and Machine Intelligence 2020
论文链接:Focal Loss for Dense Object Detection | IEEE Xplore
论文代码:https://github.com/facebookresearch/Detectron

1 | @inproceedings{lin2017focal, |
2. 归纳总结
| 标签 | 目的 | 方法 | 总结 |
|---|---|---|---|
| #Anchor #单阶段 | 解决正负样本严重不均衡的问题 | retinanet和focal loss | 针对训练过程中的实际问题,修改损失函数以达到优化的目的 |
3. 主要工作
作者认为之前的单阶段检测算法精度不高的原因可能是前后景类别(正负样本)严重不均衡导致的。因此作者重新设计了一个损失:Focal Loss,其能降低可以较好分类的样本的损失权重,防止训练过程中大量的easy negatives给检测器带来的压制影响,并基于Focal Loss设计提出并训练了RetinaNet。
3.1 网络结构
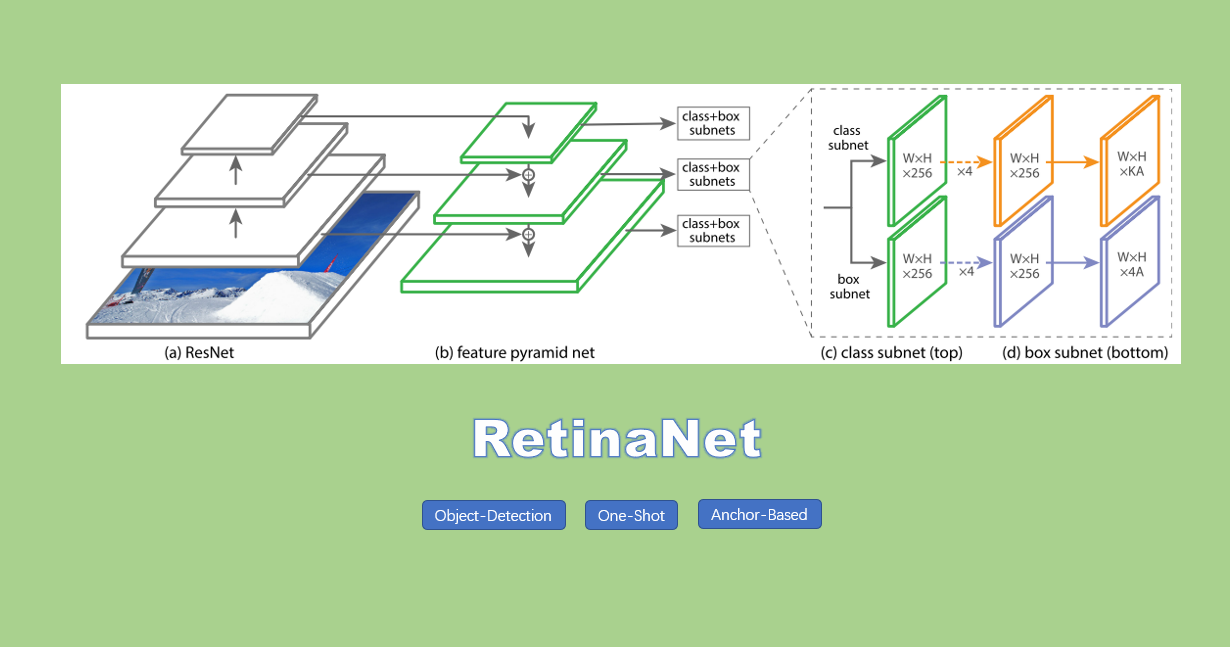
RetinaNet的结构如下图:
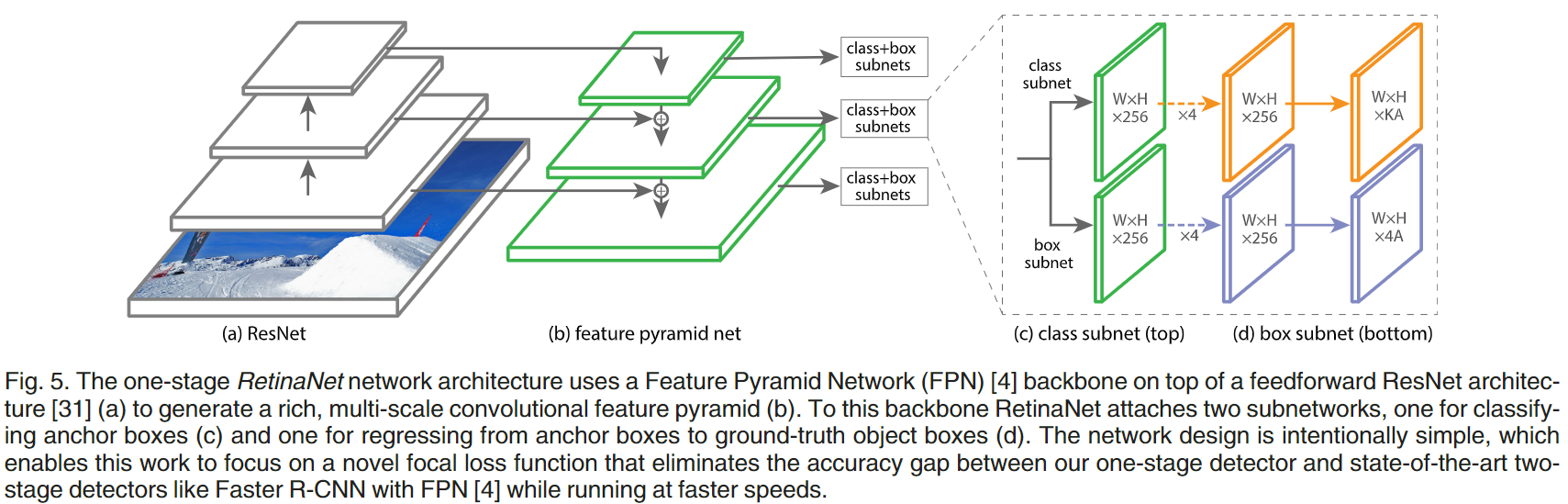
主要包括三个部分:
- Backbone:使用了ResNet+FPN,用于生成多尺度{p3~p7}卷积特征图
- Anchor:p3-p7特征图的base_size设置为$[32^2,64^2,128^2,256^2,512^2]$,在每一层特征图针对denser scale coverage,设置{${2^0,2^{1/3},2^{2/3}}$}三种不同的anchor size,比例为{1:2,1:1,2:1},即每个位置9种Anchor。
- subnets:用于分类和回归,结构相同但参数不共享的小型FCN结构
3.2 Focal Loss
作者提到基于R-CNN模式的两阶段算法在解决训练过程中的正负样本不均衡的方法是:
- 两阶段级联:在proposal阶段过滤掉大量负样本
- 启发式采样:例如固定正负样本比例(例如1:3)或者在线难样本挖掘(Online Hard Example Mining,OHEM)
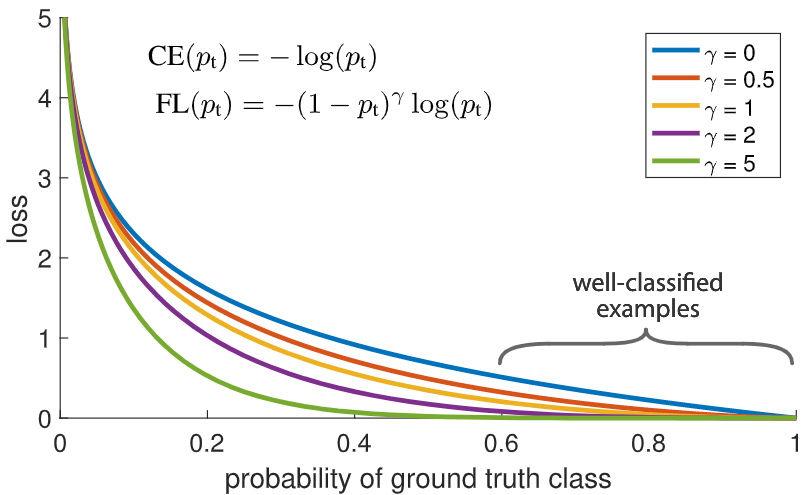
Focal loss的做法是设置一个sacling factor,如下图的$(1-p_t)^{\gamma}$,其可以自动的对easy example进行降权,从而使模型更关注hard example。
首先,对于二分类任务,普通的交叉熵如下:
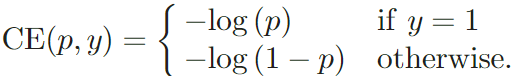
如果定义$p_t$:

那么交叉熵可以写成$CE(p,y)=CE(p_t)=-log(p_t)$
有一种常见的用于解决类别不均衡的方法是添加一个权重变量$\alpha \in [0,1]$:
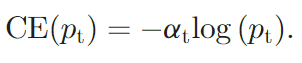
Focal Loss的做法是添加了一个权重变量$(1-p_t)^{\gamma}$:
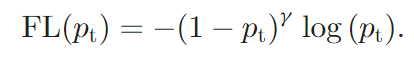
因此当$p_t$趋近于1时,可以较好分类的样本被降权;而$\gamma$可以用来调节权重比率。除此之外,还可以将$\alpha$和FL损失相结合:

除此之外还有其他的Focal Loss变种形式。
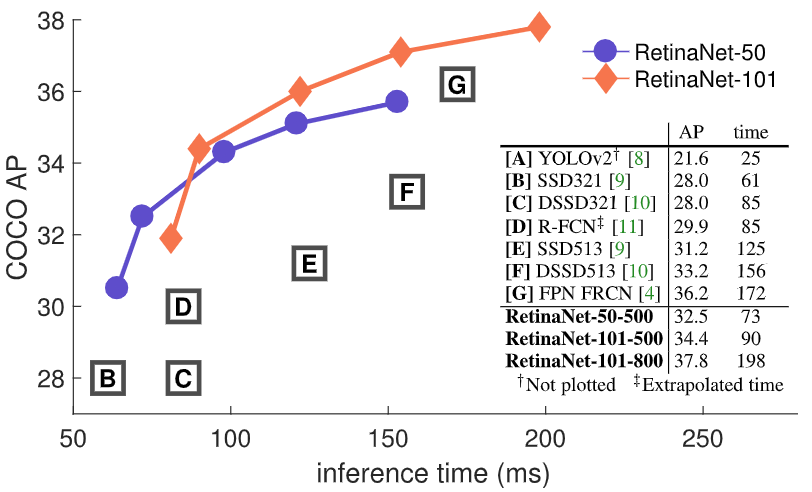
4. 实验结果