Lifelong Zero-Shot Learning(论文翻译)
终身零样本学习
作者:Kun Wei, Cheng Deng, Xu Yang
https://www.ijcai.org/Proceedings/2020/0077.pdf
摘要
零样本学习(Zero-Shot Learning, ZSL)解决了一些测试类别在训练集中从未出现的问题。现有的零样本学习方法是被设计用来从一个固定的训练集中学习的,不具备对多种训练集的知识进行捕获和积累的能力,因此不适合许多现实生活中的应用。在本文中,我们提出了一种新的零样本学习方法,称为终身零样本学习(Lifelong Zero-Shot Learning,LZSL),其目的是在多种数据集的学习过程中积累知识,并对所有训练数据集的从未出现的类别进行识别。此外,我们提出了一种革新的方法用来实现终身零样本学习,有效地缓解了连续训练过程中的灾难性遗忘。针对包含不同语义嵌入的数据集,我们利用变分自动编码器实现统一的语义表示。然后,在微调整个模型时,我们利用选择性再训练策略来保留先前任务的训练权重,并避免负迁移。最后,利用知识蒸馏,将之前的训练阶段的知识转移到当前阶段。我们还设计了终身零样本学习评估协议和高要求的基准。在这些基准上的大量实验表明,当现有的零样本学习方法失败时,我们的方法有效地解决了零样本学习问题。
1. 介绍
在最近几年,零样本学习在计算机视觉和机器学习社区中获得了越来越多的关注。与在训练阶段要求所有类别都有足够的样本的传统的分类任务不同,零样本学习的目标是识别在训练阶段从未出现过的新的类别的样本。在流行的零样本学习方法中,学习模型只在单个数据集的可见类上进行训练,然后在同一数据集的不可见类上进行测试,该数据集的可见类和不可见类是不相交的。然而,在许多现实世界的应用中,识别系统需要具有从获得的训练数据中不断学习的能力,并以终身的方式改进系统。
为了满足这一要求,我们提出了一种更实用的零样本学习方法,称为终身零样本学习(Lifelong Zero-Shot Learning,LZSL),它要求模型积累不同数据集的知识,并对所有面向数据集的未出现的类别进行识别。如图1所示,该模型在多个学习阶段进行训练,每个阶段都包含来自新数据集的图像和语义嵌入。这些数据集的语义嵌入是多样而复杂的,例如,这些数据集的属性列表是不同的。在完成所有训练阶段后,模型将对所有数据集上的可见的和不可见的测试图像进行评估。
主流的零样本学习方法旨在学习图像之间的映射和相应的语义嵌入。这些方法根据分类空间可分为三种类型,即视觉空间、语义空间和常见嵌入空间。除此之外,还有一些零样本学习方法通过训练生成模型来获取不可见的类别的特征。然后,利用可见类别的视觉特征和生成的不可见类别的视觉特征训练分类器。这些方法将零样本学习任务转换为监督学习任务。然而,这些方法不能有效地处理终身零样本学习问题,因为它们缺乏在没有排查的情况下从之前训练的任务中积累知识的机制。
为了解决上述问题,实现终身零样本学习,我们提出了一种将统一语义嵌入、选择性再训练和知识蒸馏策略无缝集成的新方法。选择交叉和分布对齐变分自编码器(Cross and Distribution Aligned VAE, CACD-VAE)作为基础模型,训练VAEs [Kingma and Welling, 2013]分别对视觉嵌入和语义嵌入的特征进行编码和解码,并使用学习到的潜在特征训练一个零样本学习分类器。为了使CACD-VAE具备终身学习的能力,我们首先利用训练后的VAEs在每个训练阶段获得统一的语义嵌入。利用统一的语义嵌入,分别学习和固定不同任务的潜在空间。为了保证视觉特征能够准确地投射到固定的潜在空间中,利用选择性再训练策略提高了不同任务的分类空间之间的相似性,也避免了在获取新任务知识过程中的负迁移。此外,知识蒸馏被用来将知识从之前的任务转移到当前任务。大量的实验表明,当其他最先进的零样本学习方法无效时,我们的方法可以有效地从之前学习的任务中积累知识并缓解灾难性遗忘。我们的方法的贡献总结如下:
据我们所知,我们是第一个提出并解决终身零样本学习问题的。我们以一种新颖的方式设计了终身零样本学习的基准和评估协议。
针对不同数据集的异构语义嵌入的挑战,我们采用了可以固定相应任务的潜在空间的VAEs算法去获得统一的语义嵌入。
利用选择性再训练提高不同数据集的分类空间之间的相似性,并通过知识蒸馏损失来监督,规范了知识从之前的任务向当前任务转移的过程。
在提出的基准上的大量的实验结果证明了我们提出的方法的有效性,它显著优于最先进的零样本学习方法。
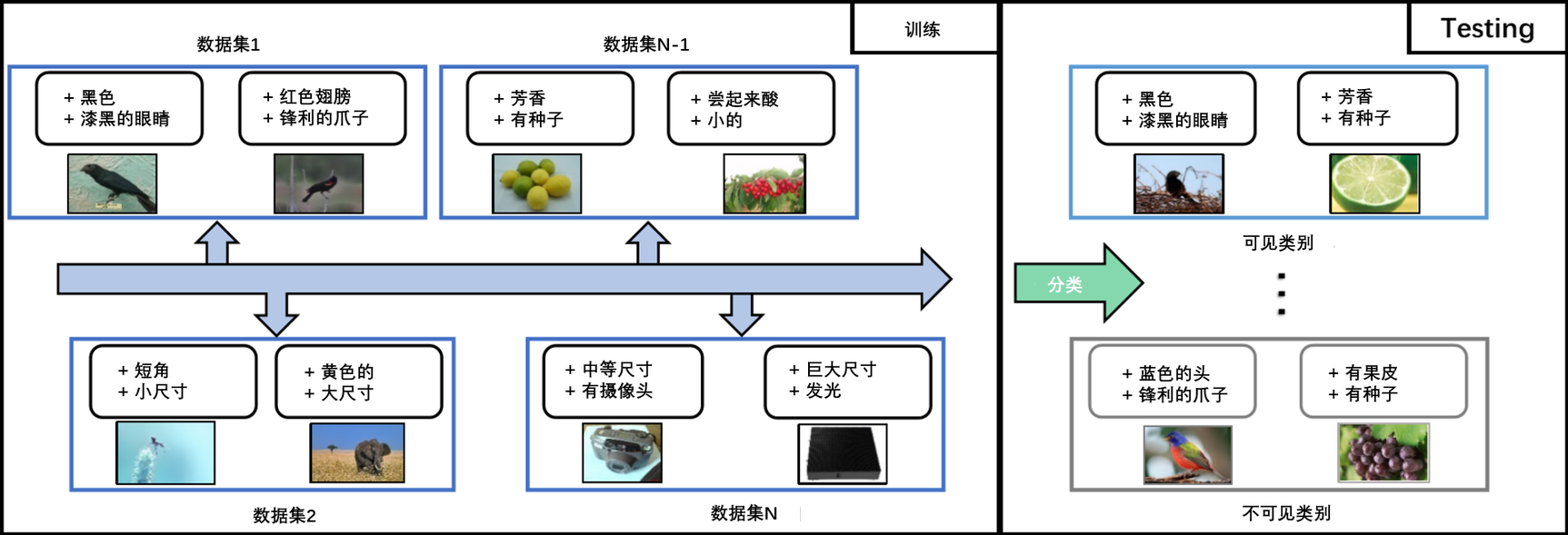
图1:终身零样本学习的概述。当新任务到来时,模型按顺序学习新任务,从所有面临的任务中积累知识。将先前任务中的知识转移到当前任务中,可以有效地对不同数据集的不可见的类别进行分类。
2. 相关工作
2.1 零样本学习
零样本学习已经成为一个热门的研究课题,其目标是在没有任何标记的训练数据的情况下识别不可见的类别。此外,零样本学习是迁移学习的一个子问题,其重点是将知识从可见的类别转移到不可见的类别。在测试阶段,测试样本从视觉空间中获取,而我们只在语义空间中进行不可见的类别的语义嵌入。因此,零样本学习方法的主流方法是构建视觉空间与语义空间的连接。典型的方法是学习将视觉特征和语义特征映射到一个共同的嵌入空间的函数,在这个空间中视觉特征和语义特征的嵌入是匹配的。最近,生成对抗网络(GANs)被提出并成功引入到零样本学习问题中。生成零样本学习方法的任务是根据语义特征生成不可见的类别的视觉特征,将零样本学习转换为传统的监督分类任务。例如,f-CLSWGAN是利用conditional Wasserstein GANs提出的,它生成了差别性的不可见的视觉特征。基于f-CLSWGAN, Cycle-WGAN 重建正则化的目的是,保留转移过程中的类别的不同特征。
然而,上述所有方法都仅在单个数据集上进行训练,因为顺序学习各种数据集的能力有限。据我们所知,我们是第一个提出并解决终身零样本学习问题的。
2.2 终身学习
终身学习(Lifelong Learning)是一种学习模式,它要求模型拥有从一系列任务中进行学习,并能将从之前任务中获得的知识转移到后续任务中的能力。终身学习的关键挑战是灾难性遗忘,即当新任务到来时,被训练的模型会忘记之前任务中得到的知识。有很多终身学习的方法被提出,主要分为三部分,即,存储之前任务的训练样本,新任务到来时的正则化参数更新,以及使用额外的生成模型来重现之前任务的训练样本的记忆重现。
与传统的终身学习问题不同的是,在流行的终身学习分类问题中,传统的终身学习问题的训练和测试的类别是相同的,而在终身零样本学习中,这些是不相交的。
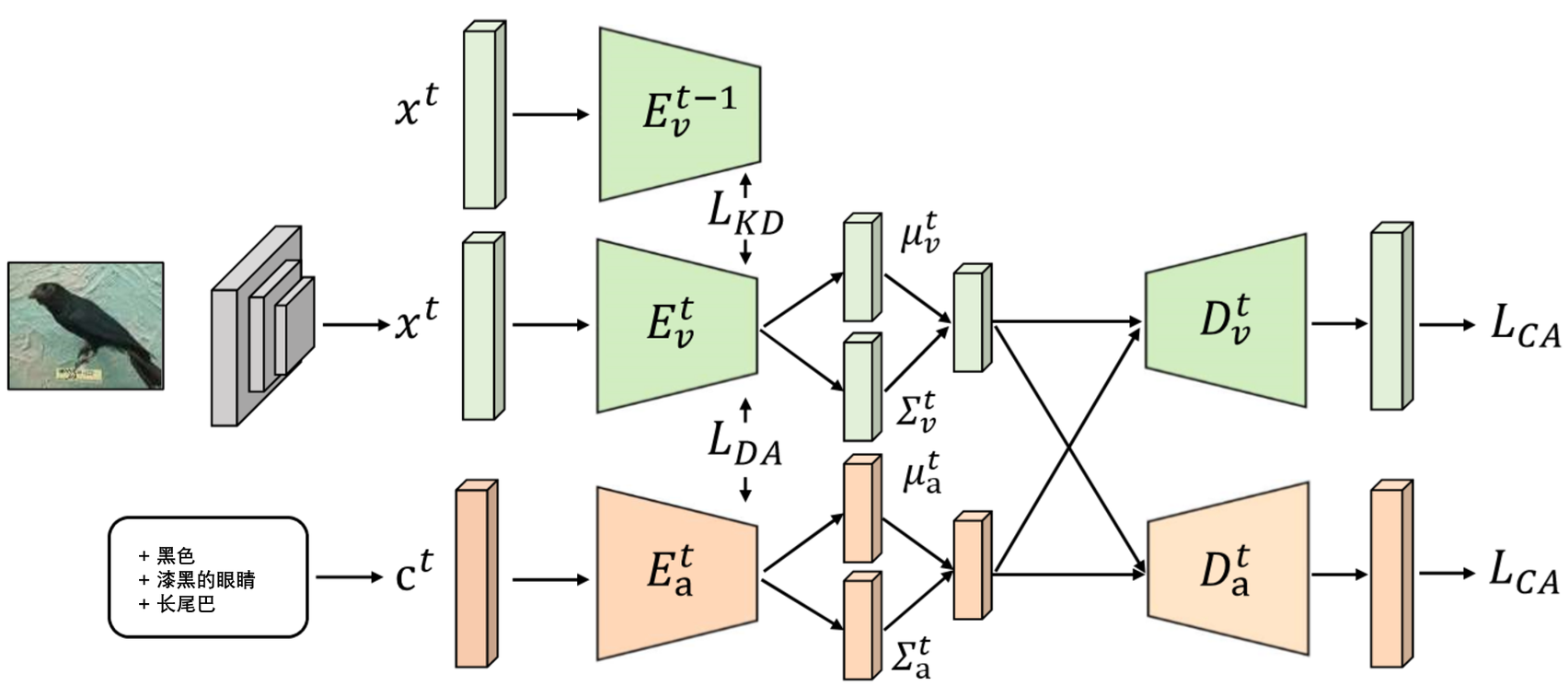
图2:我们提出的在$t^{th}$训练阶段上方法框架,该框架由两个VAEs和一个在$(t−1)^{th}$训练阶段训练过的视觉模态编码器组成。给定一张图像,视觉特征提取器可以捕获它的视觉特征$x^t$,映射到的潜在空间作为$\mu^t_v$和$\sum^t_v$。同时,相应的语义嵌入$c^t$映射到潜在的空间作为$\mu^t_a$和$\sum ^ t _ a$。 为了实现潜在的分布对齐,在训练阶段将潜在分布之间的Wasserstein距离($L _ {DA}$)最小化。然后,利用交叉对齐损失( $L _ {CA}$ ),通过交叉模态重构,来保证潜在分布的对齐。此外,我们利用知识蒸馏( $L _ {KD}$ )将之前任务中获得的知识转移到当前任务中。
3. 方法
针对终身零样本学习问题,我们提出终身零样本学习方法,将终身学习和零样本学习无缝结合。我们的方法框架如图2所示。首先,我们利用VAEs实现不同数据集的统一语义嵌入;然后,我们采用选择性再训练策略逼近不同数据集的分类空间,避免负迁移。最后,我们采用知识蒸馏的方法,将先前任务中的知识转移到当前任务中。
3.1 问题公式
在第$t^{th}$个训练阶段,给出一个数据集$S^t = {(x^t, y^t, c^t)|x^t \in X^t, y^t \in Y^t_s, c^t \in C^t }$, 其由一个预训练卷积神经网络(CNN)提取的图像特征$x^t$、可见的类别$Y^t_s$的标签$y^t$和对应类别的语义嵌入$c^t$组成。此外,还有一个可获得的数据集$U^t= {(u^t, c^t_u) | u^t \in Y^t_u, c^t_u \in C^t }$,该数据集包含集合$Y^t_u$中的不可见的类别的标签$u^t$和不可见的类别的语义嵌入$c^t_u$。对于最现实和最具挑战性的广义零学习(Generalized Zero-Learning, GZSL),其目标是学习一个分类器$f^t_{GZSL}: X^t \rightarrow Y^t_s\cup Y^t_u$。然而,我们的方法主要集中在通过顺序训练不同的数据集来学习一个生成模型,然后针对不同的数据集构造几个分类器。
3.2 背景: 交叉分布对齐变分自编码器(CACD-VAE)
本文首先介绍了一种最先进的零样本学习方法–交叉分布对齐变分自编码器 (CADA-VAE),它是我们方法的基本模型。它的目标是搜索一个共同的分类空间,其中嵌入的语义特征和视觉特征是一致的。该模型包含两个VAEs,一个用于语义特征,另一个用于视觉特征,每个都包含一个编码器和一个解码器。每个VAE的目标函数是给定样本的边际似然的变分下界,它可以表述为:
$$ L = \mathbb{E} _ {q_{\phi} (z|x)}\left[\log p_{\phi} (x|z)\right] - \lambda D_{KL}(q_{\phi} (z|x)||p_{\theta} (z)), (1) $$
其中,第一项为重构损失,第二项为解开的Kullback-Leibler散度,对推理模型$q(z|x)$和$p(z)$进行规则化。此外,$\lambda$被用来加权KL-散度。编码器预测$\mu$和$\sum$,所以有$q_{\phi}(z | x) = N(\mu, \sum)$,并且通过应用重新参数化技巧获取一个潜在的向量$z$。编码器被用于将特征投影到公共空间,并且解码器用于重建原始数据。
整个模型的VAE损失是两个VAE基本损失的总和:
$$ L_{VAE} = L_{VAE}^a + L_{VAE}^v, (2) $$
其中$L_{VAE}^a$和$L_{VAE}^v$分别表示语义模态和视觉模态的VAE损失。此外,针对语义空间和视觉空间的嵌入在公共空间中的匹配问题,该模型对潜在分布进行了精确对齐,需要一个交叉重建准则来保证。因此,我们设计并应用了交叉对齐损失(CA)和分布对齐损失(DA)。
交叉对齐损失使来自另一个模态的重构特征与原始模态特征相似。交叉对齐损失为:
$$ L_{CA} = \left| c-D_a(E_v(x)) \right| + \left|x-D_v(E_a(x))\right|, (3) $$
其中,$c$、$D_a$和$E_a$是语义模态的特征、解码器和编码器,$x$、$D_v$和$E_v$是视觉模态的特征、解码器和编码器。
利用分布对齐损失最小化语义模态的潜在高斯分布与视觉模态的之间的Wasserstein距离,使语义空间和视觉空间的隐性嵌入相匹配。
距离表示为:
$$ L_{DA} = (||\mu_a - \mu_v||_2^2 + ||\sum^{\frac{1}{2}}_a-\sum_a^{frac{1}{2}}||^2_Frobenius)^{frac{1}{2}} , (4) $$
其中$\mu_a$和$\sum_a$通过编码器$E_a$预测,而$µ_v$和$\sum_v$通过编码器$E_v$预测。
目标函数可以表示为:
$$ L_{CACD - VAE} = L_{VAE} + \gamma L_{CA} + \delta L_{DA}, (5) $$
其中,$\gamma$ 和 $\delta$ 是交叉对齐和分布对齐损失的超参数,用于权衡这些损失。
3.3 统一的语义嵌入
由于不同数据集的属性数量和种类不同,首先需要解决的挑战是不同数据集的语义嵌入是多种多样和复杂的。为了解决这一问题,我们尝试寻找不同数据集的统一语义嵌入。在训练$t^{th}$任务之后,语义嵌入$c^t$被预测为通过$E^t_a$映射的$\mu^t_a$和$\sum^t_a$。隐向量z是采用再参数化的技巧生成的,其过程是从点数据生成各种隐向量的过程。生成的隐向量可以作为最终分类器的训练数据,其中包含了对应类的判别信息。在此基础上,我们替换原始语义嵌入$c^t$和$\mu^t_a$,$\sum_a^t$,从一个点数据到两个点数据,数据可被视为更具代表性的语义映射。在训练完所有任务后,我们可以利用这些新的语义嵌入再现所有数据集的隐向量,并训练更强健的分类器。
3.4 选择性再训练
对于这项新任务,一种自然的方法是对整个模型进行微调。然而,对整个模型进行微调会改变先前任务的权重,导致神经网络的灾难性遗忘。因此,我们采用选择性再训练策略对整个模型进行微调。当获得统一的语义嵌入时,不同数据集的分类空间是固定的,这也是之前任务的潜在空间。因此,模型是从视觉空间到分类空间的投影,是视觉模态的编码器$E_v^t$。我们表示$W^t$作为$E^t_v$和$W^t_l$的参数,被表示为l层的参数,而l层的数量是L。当一个新的任务到达时,我们首先冻结参数$W^{t - 1}_l$,并对模型进行微调,以获得$L - 1$层之间输出单元$o_t$和隐藏单元的连接。然后,我们可以选择在训练过程中受影响的所有单位和权重,并保持与输出单位无关的部分不变。选择操作可以看作是对模型进行初始化,保证优化的方向是保护前一个任务的分类空间。最后,我们只对选定的权值进行微调,记为$W_S^t$。算法1描述了选择性再训练的过程。
| 算法1 选择性再训练的过程 |
|---|
| 输入:数据集$S^t$,之前的参数$W^{t-1}$ |
| 输出:选择参数$W_s^t$ |
| 1: 冻结参数$W^{t-1}_L$,$S^t={o_t}$ |
| 2: 微调网络 |
| 3: $\text{for l = L,…,l do}$ |
| 4: 添加神经元$i$到$S^t$,如果存在一些神经元$j \in S$,且$W_{l,ij}^{t-1}≠0$ |
| 5: $\text{end for}$ |
| 6: 微调选择的参数$W^t_S$ |
3.5 知识蒸馏
通过选择性再训练,选择性神经元发生变化并且其他神经元被冻结,但不能保证整个模型的优化方向,即激励模型保持之前任务的知识。为了将知识从之前的任务中转移到当前任务中,我们采用了知识蒸馏策略。当$t^{th}$任务到达时,我们希望在相同输入$x^t$的情况下,$E^t_v$的输出与$E^{t−1}_v$的输出相似,这样可以保证$t^{th}$任务和$(t-1)^{th}$任务的分类空间近似。在顺序训练所有数据集后,当$E_v^t$输入相同的图像特征$x^t$时,最后的$e_v$有能力预测相似的$\mu^t_v$和$\sum^t_v$。蒸馏损失记为:
$$ L_{KD} = ||\mu_v^t - \widehat{\mu _v^t}||_1 + ||\sum_v^t - \widehat{\sum_v^t}||_1 , (6) $$
其中$\mu_v^t$和$\sum_v^t$通过$E^t_v$预测,而$\widehat{\mu_v^t}$和$\widehat{\sum_v^t}$通过$E^{t-1}_v$。
当$t>1$时,目标函数表示为:
$$L = L_{CACD-VAE} +\beta L_{KD}, (7) $$
其中$\beta$为加权知识蒸馏损失的超参数,设为1。
3.6 训练和推理
在训练中,我们对数据集进行顺序训练,并保存所有类别的统一语义嵌入。
在VAEs的训练阶段结束后,我们利用保存的语义嵌入再现所有类的隐向量。隐向量的生成过程对每个可见类别重复$n_s$次,对每个不可见类别重复$n_u$次。$n_s$和$n_u$分别设置为200和400。这些隐向量包含了这些类别的判别信息。利用不同数据集的隐向量分别训练softmax分类器。
在测试阶段,通过视觉模态$E_v$编码器将被测试可见类和不可见类的视觉特征投影为隐向量。然后将测试特征输入到训练好的分类器,得到不同数据集的分类结果。
| 数据集 | 语义维度 | 图像 | 可见类 | 不可见类 |
|---|---|---|---|---|
| APY | 64 | 15339 | 20 | 12 |
| AWA1 | 85 | 30475 | 40 | 10 |
| CUB | 312 | 11788 | 150 | 50 |
| SUN | 102 | 14340 | 645 | 72 |
表1:实验使用的数据集及其统计信息。
4. 实验
在本节中,我们将详细介绍所涉及的数据集、评估指标和实现细节。然后,我们将呈现几个最先进的竞争对手以及我们的方法的实验结果。最后,消融研究将证明我们所提出方法的有效性。
4.1 基准和评估标准
我们在四个数据集上评估我们的方法: Attribute Pascal和Yahoo数据集(aPY),Animals with Attributes 1 (AW A1),Caltech-UCSD-Birds 200-2011数据集(CUB)和SUN Attribute数据集(SUN)。数据集统计如表1所示。对于所有数据集,我们使用预先训练的101层的ResNet提取2048维视觉特征。训练数据集的顺序为aPY, AWA1, CUB和SUN,都是按字母顺序排列的。
遵循广义零样本学习方法,我们对终身零样本学习采用相同的评价指标:
u:是对每类带有预测标签集的不可见类别的测试图像进行分类的平均准确率,用于衡量识别不可见类的能力。
s:是对每类带有预测标签集的可见类的测试图像进行分类的平均准确率,用于衡量识别增量可见类的能力。
H:u和s的调和均值,公式为:$H=\frac{2×u×s}{u+s}$。
我们任务中最重要的指标是,H平衡u和s指标之间的性能。对所有数据集进行训练后,对三个度量的所有结果进行测量。
4.2 实施细则
所有的编码器和解码器都是多层感知机,有一个隐藏层。我们使用了1560个隐藏单元作为图像特征编码器,1660个作为解码器。编码器和解码器的属性分别有1450个和660个隐藏单元。$\delta$从第6个epoch到第22个epoch以每轮0.54的速率增加,而$\gamma$从第21个epoch到第75个epoch以每个epoch按0.044的速率增加。KL散度的权重$\lambda$以每个epoch按照0.0026的速率增加,直到第90个epoch。此外,我们使用L1距离作为重构误差,得到了比L2更好的结果。
对于每个数据集,epoch的数量设置为100,批处理大小(batch size)设置为50。VAEs学习率设置为0.00015,分类器学习率设置为0.001。另外,我们的方法是用PyTorch实现的,并通过ADAM优化器进行优化。
4.3 与现存基准程序的比较
基线模型。由于之前没有关于终身零样本学习的研究,我们将结合了CACD-VAE与传统的终身学习方法的基线进行比较。
(a) 顺序微调(SFT): 当一个新任务按顺序到达时,模型被微调,该模型的参数从在前一个任务训练或微调的模型进行初始化。
(b) L2正则化(L2): 在每个任务t上,$W_t$初始化为$W_{t−1}$,在$W_t$和$W_{t−1}$之间持续进行L2正则化训练。
(C) L1正则化(L1): 在每个任务t上,$W_t$初始化为$W_{t−1}$,在$W_t$和$W_{t−1}$之间持续进行L1正则化训练。
结果和分析。表2总结了在四个基准数据集上的所有的对比方法以及我们的方法在三个评价指标下的结果。对于GZSL指标上的零样本学习方法,H是评价零样本学习方法性能最重要的指标,它平衡了u和s指标的性能。
表2中的“Base”表示模型在没有任何终身策略的情况下按顺序训练,“Original”表示分别训练数据集的模型。显然,我们可以发现Base的结果获得了之前数据集的最差性能,当新任务到来时,这些数据集不具备积累之前数据集的知识的能力。此外,采用顺序微调策略的模型比不采用该策略的模型的结果更差,这表明了零样本学习中存在灾难性遗忘问题。
与其他基准相比,我们的方法在前三个数据集中获得了三个评价指标的最佳性能。在aPY数据集上,我们的模型的u达到了29.11%,s达到了43.29%和H达到了34.81%,其中u提升了2.69%,s提升了13.50%,并且H提升了6.80%。在AWA1数据集上,我们的模型的u达到了51.17%,s达到了63.66%和H达到了56.73%,其中u提升了1.53%,s提升了4.59%,并且H提升了3.14%。在CUB数据集上,我们的模型的u达到了38.82%,s达到了45.81%和H达到了42.03%,其中u提升了3.29%,s提升了11.07%,并且H提升了7.68%。尽管我们的方法没有在SUN数据集上获得最好的结果,但是与其他数据集的改进相比,结果只下降了很少,这是因为我们的方法更好地平衡了从之前任务积累知识的能力以及当前任务获取知识的能力。我们还计算了这些方法在四个数据集上的平均H值。Base、SFT、L1、L2以及我们方法的平均H值分别为10.2%、36.73%、38.03%、36.73%和42.48%,平均H值提高了4.45%。综上所述,我们的方法在之前任务和当前任务中获得了均衡的性能,并且明显优于基线程序。
4.4 消融研究
我们进行了两组消融实验来研究我们方法的有效性。
表3显示了添加了不同模块的基本模型的结果。基本模型为使用了连续微调训练策略的CACD-VAE。在基础模型的基础上,加入知识蒸馏模块和选择性再训练模块,分别用“KD”和“SR”表示。如表3所示,知识蒸馏和选择性再训练都可以提高前三个数据集的性能。加入“KD”的改进表明知识蒸馏可以将前一个任务的知识转移到当前任务中,在一定程度上缓解了灾难性遗忘的不利影响。此外,添加“SR”的改进表明选择性再训练可以保留之前任务中受影响的权重,避免负迁移,因为没有被选择的神经元不会受到再训练过程的影响。当添加所有模块时,我们的方法表现得最好。
我们做了一个实验来讨论数字$n_s$和$n_u$重放的影响,其平均H结果如图3所示。
当$n_s$和$n_u$被设置为200和400时,可以获得最佳性能。显然,我们可以注意到一个现象:在平均H达到峰值性能之前,平均H随着$n_s$和$n_u$的增加而增加。
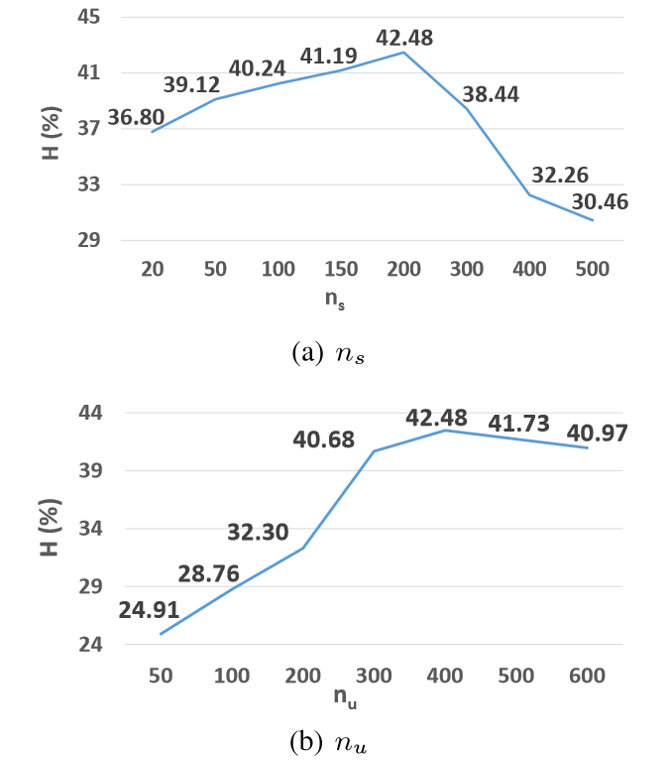
图3:不同$n_s$和$n_u$超参数下的平均H结果。
5. 结论
据我们所知,本文是第一个尝试介绍和解决终身零样本学习的。首先,我们采用VAEs方法获得统一的语义嵌入,从而弥补了不同数据集语义嵌入之间的差距。然后,利用选择性再训练策略,在很大程度上保留前一训练阶段构造的投影。最后,我们从之前的任务中提炼出知识,并转移到当前的训练阶段。实验结果表明,该方法在4个基准数据集上性能均明显优于以往的方法。